
A robots.txt alkalmazása a kezdő weboldaltulajdonosoknak kicsit ijesztő lehet. De ne aggódj, közérthetően összefoglalok minden fontos tudnivalót, figyelembe véve a keresőoptimalizálási szempontokat.
Mi az a robots.txt?
A robots.txt egy sima szövegfájl, amivel a weboldaltulajdonos szabályozhatja, hogy a keresőrobotok, (így a Google) hogyan térképezze fel a weboldaladat.
Minden weboldalnak:
- csak egyetlen robots.txt fájlja lehet
- ezt a weboldal főkönyvtárában kell elhelyezni
Hova kell elhelyezni a robots.txt fájlt?
Mindig a weboldalad gyökérkönyvtárába, vagy főkönyvtárába kell elhelyezni a robots.txt filet.
Az enyémet például itt találod: https://ite.hu/robots.txt
Fontos, hogy a keresőrobotok is mindig ezen a helyen keresik ezt a fájlt. Ha itt nem találják, akkor azt feltételezik, hogy nincs a weboldalnak robots.txt file-ja, és automatikusan feltérképezik a teljes weboldaladat.
Hirdetés

Miért van szükség a robots.txt fájlra?
Az első, amit tudnod kell, hogy a robots.txt fájl használata nem kötelező. Ugyanakkor ha szabályozni akarod a keresőrobotok működését, akkor szükséged lehet rá. Nézzük mire használják leggyakrabban a robots.txt filet?
- a duplikált tartalom feltérképezésének és leindexelésének megakadályozása (erre a meta robots jobb választás lehet)
- weboldalad egy részének priváttá tétele
- a weboldalon futatott keresési eredmények URL-jeinek feltérképezési korlátozása
- webhelytérkép helyének megadása
- bizonyos fájltípusok (pdf, ppt, stb.) feltérképezésének megakadályozása
- a feltérképezési gyakoriság késleltetése annak érdekében, hogy megakadályozzuk a szerver túlterhelését
A robots.txt fájl tartalma
A robots.txt-ben alapvetően azt szabályozzuk, hogy a különböző típusú keresőrobotok, webfeltérképező programok, amiket user-agent névvel illetünk hozzáférhetnek, vagy sem a weboldal bizonyos részéhez. Ez utobbi szabályozására az alábbi két parancsot használjuk:
- allow (engedélyezés)
- disallow (tiltás)
Nézzünk ez alapján ez tipikus sor a robots.txt-ből:
User-agent: [user-agent neve] Disallow: [URL nem feltérképezhető]
Konkrét példa:
User-agent: googlebot
disallow: /comments/
A fenti paranccsal a googlebot keresőrobotnak, mint user-agent-nek azt adjuk utasításba, hogy a /comments/ URL-eket ne térképezze fel.
Nézzük meg az origo.hu robots.txt tartalmát:
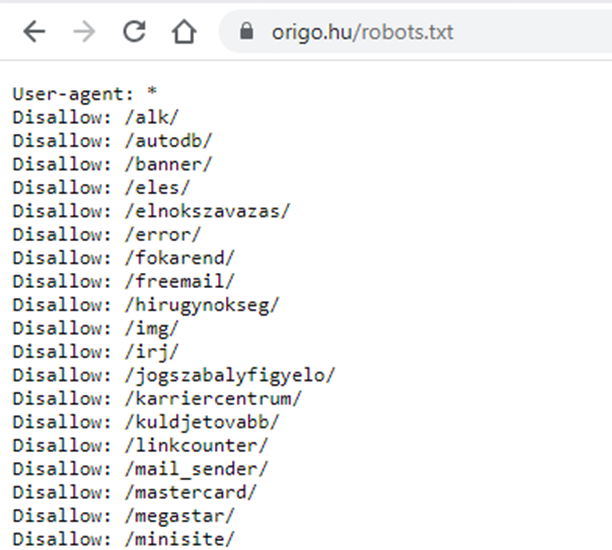
Láthatod, hogy a user-agent alatt itt egy csillag szerepel, ez azt jelenti, hogy az alatta lévő utasítás az összes webes robotra vonatkozik.
A disallow pedig megakadályozza, hogy a felsorolt mappa alatt lévő URL-eket feltérképezzék.
Példák a robots.txt használatára
Blokkolja a összes robotnak a hozzáférést a weboldal teljes tartalmához:
User-agent: * Disallow: /
Ez akkor lehet hasznos, ha egy weboldal például fejlesztés alatt áll.
Az összes robot hozzáférhet a weboldal teljes tartalmához:
User-agent: * Disallow:
A robotok hozzáférhetnek a weboldal összes tartalmához.
Egy konkrét robot hozzáférésének blokkolása egy konkrét mappához:
User-agent: Googlebot Disallow: /privat-mappa/
Itt megtiltjuk a Googlebot keresőrobotjának, hogy a „privát-mappa” könyvtár tartalmát feltérképezze.
Egy konkrét keresőrobot számára tiltjuk a hozzáférést egy konkrét URL-hez
User-agent: Bingbot Disallow: /mappa/blokkolt-oldal.html
Ennél a példánál a Bing keresőrobot számára tiltjuk meg, hogy a konkrét „blokkolt-oldal.html” URL-t feltérképezze.
Parancsok formázása a robots.txt-ben
A robots.txt-ben több parancsot is használhatunk egyszerre. Ezeket jellemzően különálló blokkokba szervezzük, amiket egy üres sor választ el egymástól.
Ez nem kötelező, de sokkal könnyebben áttekinthető így a fájl tartalma. Ez a blokkos szervezés jól látszik a moz.com robots.txt fájljában:
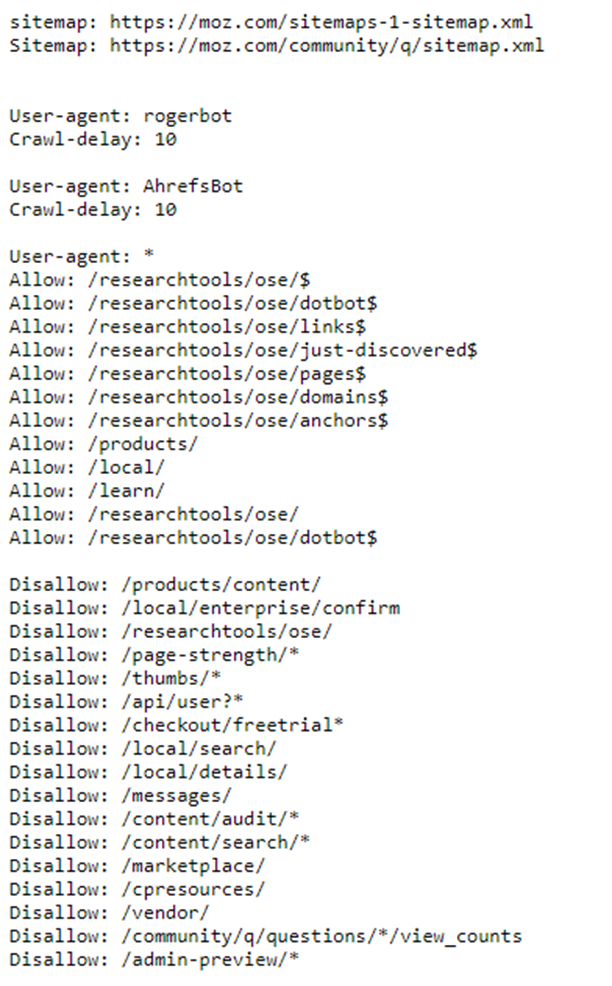
További parancsok a robots.txt-fileban
A fenti példából is látható, hogy a leggyakoribb az allow/disallow parancs. De van néhány további parancs is, amit használhatunk a robots.txt fileban
Webhelytérkép helyének megadása
Bár a webhelytérképünket a feltölthetjük a Search Console-ba közvetlenül, de megadhatjuk annak elérését a robots.txt file-ban is.
Egyszerűen használjuk az alábbi parancsot:
sitemap: https://ite.hu/sitemap.xml
Feltérképezés késleltetése
A másik gyakrabban használt parancs a feltérképezés gyakoriságának késleltetése. Ez így használhatjuk:
User-agent: Googlebot
Crawl-delay: 5
Ezzel a paranccsal arra utasítjuk a Google robotját, hogy oldalaink feltérképezésekor várjon 5 másodpercet. Erre ritkán van szükség, de egyes nagy méretű oldalaknál a keresőrobotok esetleg megterhelhetik a szervert.
Azt azonban érdemes tudni, hogy a Google 2019 óta nem veszi figyelembe ezt az utasítást és egyedileg érzékeli a szerver terheltségét, és ha úgy érzékeli, hogy túl nagy a terheltség, akkor automatikusan korlátozza a feltérképezési gyakoriságot.
Speciális karakterek a robots.txt-ben
A feltérképezés szabályozása olykor egész összetett feladat is lehet. A robots.txt-ben éppen ezért lehetőség van a reguláris kifejezések használatára.
Ennek segítségével lehetőség van nem konkrét URL-ek megadására, hanem bizonyos mintázatokat, szabályokat követő URL-típusok megadására is. A robots.txt-ben használt két kifejezés:
- dollárjel ($)
- és a csillag karakter (*)
Ezek használatára ad gyakorlati példákat a Google útmutatója.
A Robots.txt és a SEO
Az alábbiakban a robots.txt és a keresőoptimalizálás kapcsán gyakran felmerülő kérdést tisztáznék:
- Ha az oldal nem jelenik meg a Google találati listáján a site: keresésre sem, ellenőrizzük, hogy nincs-e blokkolva a robots.txt fileban az adott URL elérése!
- néha a duplikált tartarlom feltérképezésének megakadályozására használják a robots.txt-t. Ez azonban nem a legjobb megoldás. Az indexelés meggátolására használjuk a meta robots címkéket (noindex-re helyezés), vagy bizonyos duplikációknál használható a canonical illetve a href lang. Részesítsük ezeket előnyben a robots.txt-vel szemben!
- ügyeljünk rá, hogy ne blokkoljuk olyan mappák elérését, amelyek javascript, css és képfájlokat tartalmazhatnak, mert ez esetben a Google nem képes az eredeti megjelenéshez hasonlóan renderelni a weboldalunkat, és így például nem biztos, hogy jól értelmezi weboldalunk reszponzivitását!
- Ha egy URL feltérképezése tiltva van a robots.txt-ben, akkor az ide érkező és innen kifelé mutató linkek nem adják át a linkerőt!
- a robots.txt-t kis r betűvel kell írni, a Robots.txt-t figyelmen kívül hagyják a keresőrobotok!
- végül: a robots.txt ajánlásait a rosszindulatú robotok figyelmen kívül hagyják. Éppen ezért ne tárolj érzékeny adatokat egyszerűen robots.txt tiltással, hanem használj mindig jelszavas védelmet is az ilyen típusú adatoknál!
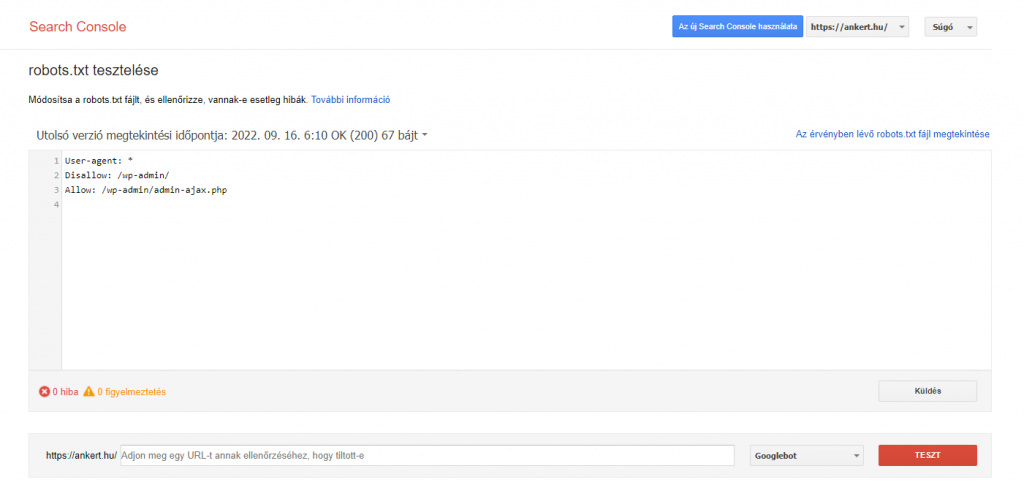
Robots.txt tesztelés és beküldése a Google Search Console-nak
A Googlenak van egy dedikált robots.txt ellenőrző eszköze, amellyel tesztelhető a robots.txt file-od. Ezzel az eszközzel:
- ellenőrizheted, hogy a robots.txt fájlod tartamaz-e hibát?
- ellenőrizheted egy konkrét URL feltérképezhetőségét
- és beküldheted a robots.txt fájlt a Google számára, ha fel akarod gyorsítani, annak ellenőrzését
WordPress és robots.txt
A WordPress telepítéskor automatikusan legenerál egy robots.txt-t, aminek ez a tartalma:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
A Yoast SEO Plugin ezt a robots.txt-t átírja az alábbi tartalomra:
User-Agent: *
Disallow:
Sitemap: https://www.example.com/sitemap_index.xml
Ez utóbbi engedélyezi a feltérképezést minden robot számára és megadja a webhelytérkép elérési útját is.
Alapvetően mind a két beállítás helyes. Ha speciális igényeink vannak azt egyedileg kell beleírni a robots.txt fájlunkba.

Töltsd le a Google 100 keresőoptimalizálási tanácsát
...és értesülj a legfontosabb SEO hírekről. 100% SEO, zéró spam.