
A szemantikus keresésről szóló cikkemben már találkozhattál a NLP-vel. Hivatalosan 2019-ben jelent meg a Google algoritmusaiban, a BERT algoritmus révén és magyar nyelven is aktív. De mi is ez pontosan és miért fontos a SEO-ban?
Ebben a cikkből megtudhatod, hogy:
- mi az a Természetes Nyelvek Feldolgozása?
- miért fontos a keresőmotoroknak?
- hogyan használhatod a napi SEO munkádban?
(Ez egy cikksorozat második része, amely a modern SEO-val foglalkozik: szemantikus SEO, entitások, NLP, Tudásgráf, stb. Ha érdekel a folytatás, iratkozz fel a hírlevélre.)
Mit nevezünk Természetes Nyelvnek?
Természetes nyelvnek (a mesterséges nyelvekkel szemben) az emberek által használt olyan nyelvet nevezzük, amely egy közösség (törzs vagy nemzet) életében nemzedékről nemzedékre spontán vagy tudatos folyamatok (például nyelvújítás) során szabadon fejlődik, változik.
Ezzel szemben a mesterséges nyelveket tudatosan hozták létre az emberek, például az eszperantó, a programozási nyelvek, vagy a klingon.
Mi az a Natural Language Processing?
Az NLP egy olyan mesterséges intelligencia, ami segíti a számítógépeket, hogy feldolgozza és megértse a természetes nyelveket.
Hirdetés

Pontosabban fogalmazva az NLP a gépi tanulás egyik ágát jelenti, amely arra törekszik, hogy jobban megértse az írott és beszélt emberi nyelvet, oly módon, hogy az emberi eredetű strukturálatlan információt a gépek által értelmezhető strukturált formába alakítja.
Ezért olyan fontos az NLP technológia az olyan keresőmotorok számára, mint a Google, hiszen korábban a keresőmotorok egyszerűen kulcsszavakat, karakterláncokat kerestek adott szövegben, ugyanakkor az NLP révén értelmezni tudják az emberi nyelveket.
Az NLP abban előrelépés, hogy nem csak a szavakat önállóan értelmezi, de képes azokat kontextusukon a többi szóval együtt, mondatként kontextusában értelmezni.
Az NLP folyamata
Az NLP-nek számos aspektusa van, én itt most csak arra összpontosítok, ami SEO szempontból fontos.
Röviden az NLP az a folyamat, amelynek során a szöveget részekre bontjuk, kapcsolatokat keresünk a szavak között, megértjük a szavak jelentését. Nézzük a folyamatot kicsit részletesebben!
Az NLP lépései
Tokenization (Tokenizálás)
A tokenizálás az a folyamat, amelynek során a szöveget kisebb részekre, un. tokenekre bontjuk.
A tokenek lehetnek szavak, karakterek, vagy un subword-ök. Nézzünk egy konkrét példát, hogy mindez világosabb legyen. a példamondatunk:
„Sose add fel!”
Ez felbontható szavakra: sose-add-fel, ezek szó-tokenek lesznek.
Ugyanakkor egy szó tovább bontható karakterekre: sose: s-o-s-e.
És mik a subword-ök? Angolban a smarter szóból a smart, magyarban a kékes, szóból a „kék”. A subwordok-et nevezik n-gram karaktereknek is.
És itt egy példa a Google NLP-jéből, ahol látható, ahogy egy mondatot a Google NLP-je szó tokenekre bont.
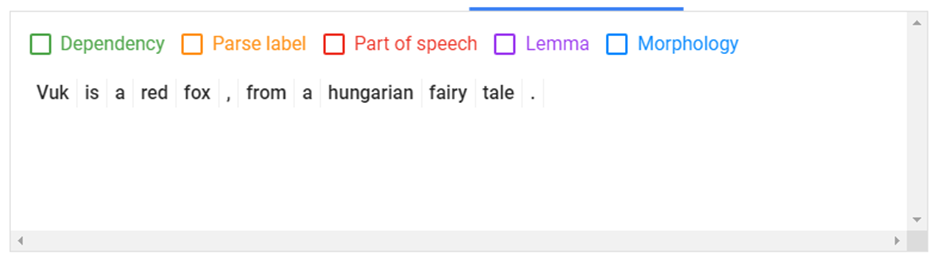
A tokenizálásról itt olvashatsz többet. Ajánlom továbbá az alábbi tanfolyamot is, ami ingyenesen elérhető angol nyelven.
De most lépjünk tovább az NLP folyamatában!
Parts-of Speech Tagging (Mondatelemzés)
Ebben a folyamatban tulajdonképpen az általános iskolából ismert módszer szerint megcímkézzük az egyes szavakat: alany, állítmány, jelző, és így tovább.
Ismét egy példa, a Google NLP-jéből:
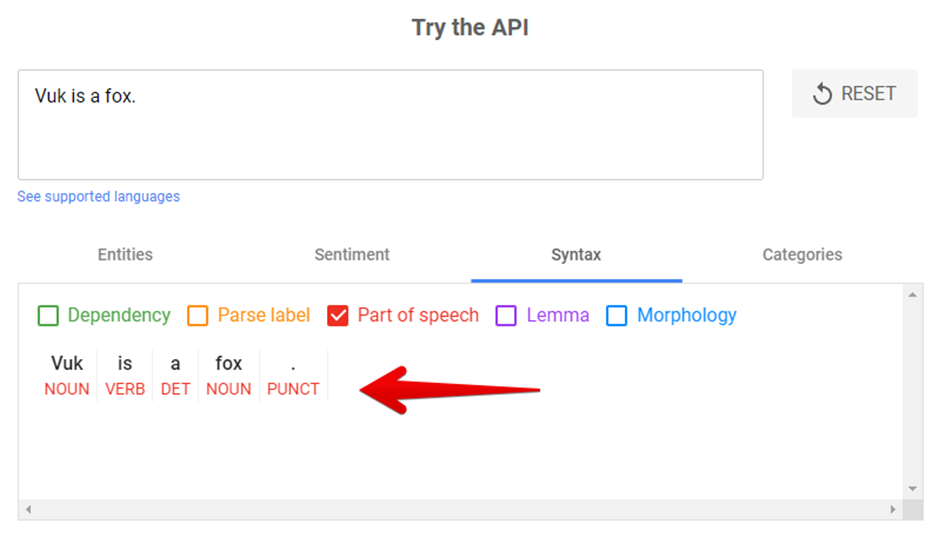
A fenti példánál látható, hogy a „Vuk is a fox.”, mondat szavait, hogy címkézi meg a Google NLP-je.
A „Vuk”, a noun, ami főnevet jelent, akárcsak a „fox”, az „is” ige, és így tovább.
Lemmatization (Lemmatizálás)
A legtöbb nyelveben a szavakhoz végződések (például ragok, képzők) társulnak, illetve a szavaknak vannak elő- és utótagjai. Ezek eltávolításával (lemmatizálás) kapjuk a szavak szótári alakját.
A lemmatizálás tehát a ragok, képzők, elő és utótagok eltávolítását jelentik.
Egy példa a lemmatizálásra angol nyelven:

Magyarul az „autója” szó lemmatizálása után megkapjuk az „autó” szót.
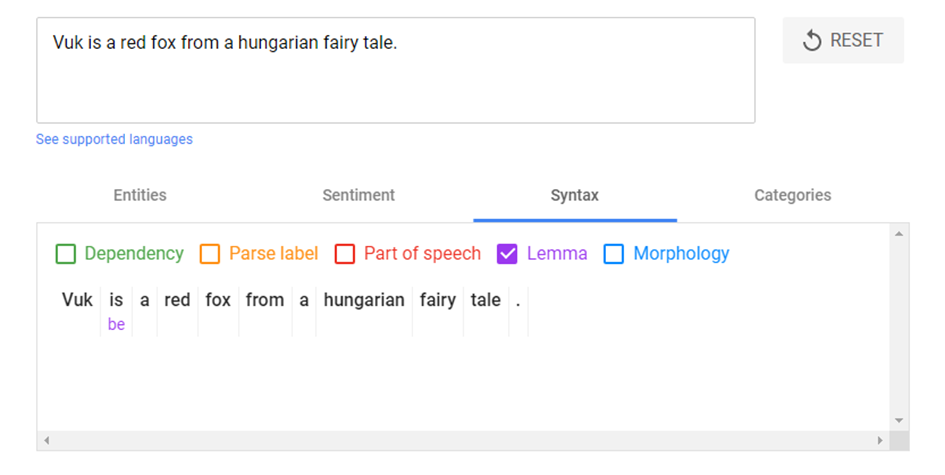
A legtöbb SEO bővítmény és eszköz emiatt nem használható jól magyar nyelven, mert képtelen a magyar ragok eltávolítására, azaz lemmatizálására. Emiatt aztán a SEO elemző szoftverek számára a „linképítés” és a „linképítéshez” külön szó lesz, nem is beszélve az olyan változásokról mint a tó-tavak páros.
Word Dependency (Szavak kapcsolódása, függése)
Ezen folyamat az NLP-ben kapcsolatokat tár fel az egyes szavak között az adott nyelv nyelvtani szabályai alapján.
Nézzünk ismét egy példát a Google Natural Language Processing-ből:
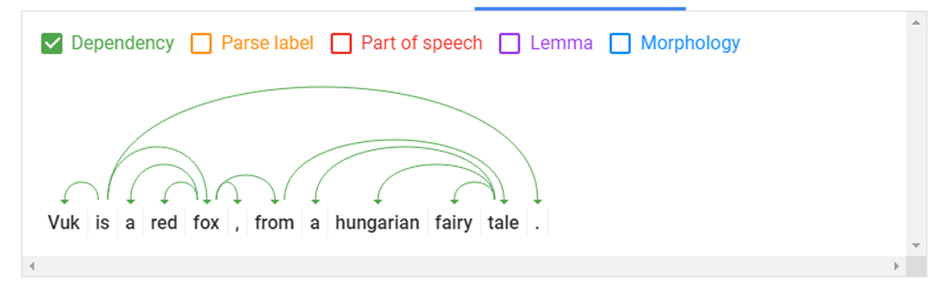
Jól látható, hogy az egyes szavak között kapcsolatok, „ugrások” vannak. A „tale” szóhoz kapcsolódik a „hungarian” és a „fairy” kifejezések.
Ez azért nagyon fontos, mert így a keresőmotor nem egyszerűen a szavakat dolgozza fel, hanem felismeri az egyes szavak kapcsolatát és kontextusát. Így pedig a felhasználó keresőkifejezésekor az összetettebb keresések is könnyebben értelmezhetőek.
Ez az angol nyelv esetében már nagyon jól működik, a magyar nyelv esetében azonban még meglehetősen kezdetleg állapotban van a tapasztalataim szerint.
Parse Label (Elemző címkézés)
A címkézés során az egyes szavak közötti kapcsolatokat, függéseket címkézi fel az NLP:
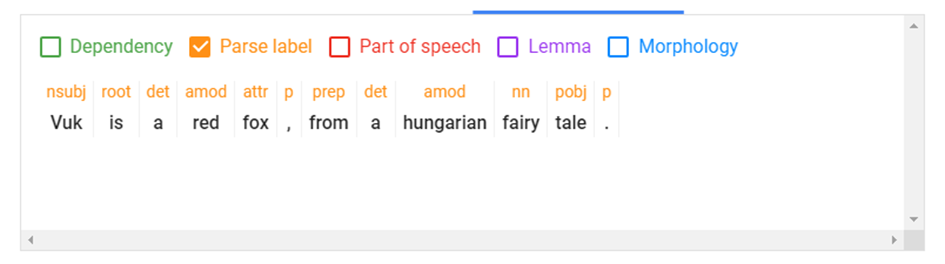
Az „nsubj”, „root”, „det”, stb. jelölések magyarázata messze meghaladná ennek a cikknek a kereteit, de álljon itt egy példa! Az „amod” jelölés például azokat a mellékneveket jelöli, amelyek módosítják az NP, azaz a főnévi kifejezés jelentését. A példamondatban a hungarian és a red szavak ilyenek, amelyek a fox és a tale szavak értelmét módosítják.
Talán ebből a példából is látható, hogy a ez a fajta címkézés, hogyan segíti a gépi algoritmusokat a mondat jobb értelmezésében
Ha érdekelne ezek a jelölések, akkor a Stanford Egyetem útmutatójában megtalálhatod ezeknek a címkéknek a jelentését.
Entitások felismerése
Ezt követően az NLP igyekszik entitásokat felismerni a szövegben. Az entitásokról a cikksorozat későbbi részeiben majd esik még szó. Itt röviden annyit, hogy az entitások jellemzően dolgok, személyek, fogalmak.
Az entitások révén a keresőmotorok nem csak szavakat látnak, hanem a szavak mögötti „dolgokat” is, amelyek különböző tulajdonságokkal rendelkeznek.
A fenti példánál a „Vuk”,„red fox” és a „fairy tale” kifejezéseket is entitásként azonosította a Google NLP.
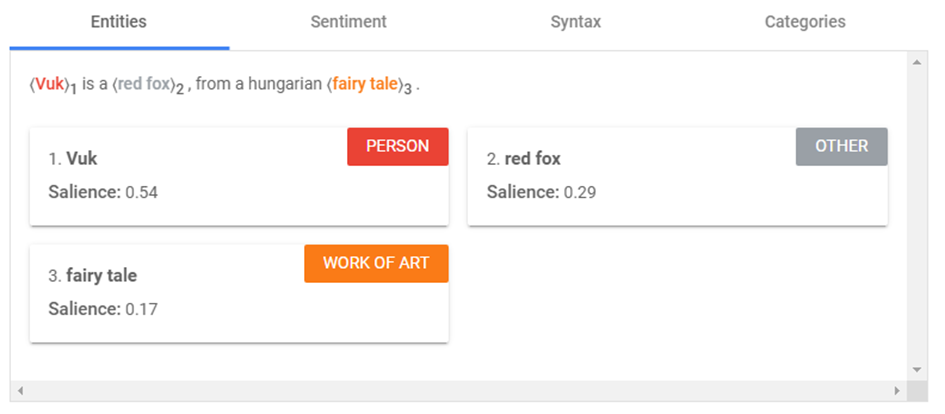
Az entitásoknak keresőoptimalizálási szempontból igen nagy jelentősége lesz majd. Ha entitásokat ír be a felhasználó a keresőbe, akkor gyakran megjelenik a tudásgráf is a találati listán. Ugyanakkor egy kifejezés akkor is lehet entitás a Google szemében, ha nem jelenik meg tudásgráf a találati listán.
Salience (Szaliencia elemzés)
A szaliencia, kiugrást, feltűnést jelent. Az NLP-ben a szaliencia azt határozza meg, hogy mennyire szól a szöveg valamiről. Hogy ez mit jelent pontosan?
Tulajdonképpen arról van szó, hogy a szaliencia megmutatja, hogy egy adott szöveg, vagy szó mennyire releváns a téma egészéhez viszonyítva.
A szalienciát a Google a web egészén egyes kifejezések együttes előfordulása alapján határozza meg. Ezen túl figyelembe veszi az egyes entitások egymáshoz való kapcsolódásának szorosságát is.
A szaliencia értéke 0-1 között alakul. Az egyes érték nagyon erős relevanciát jelez. Például látható, hogy a „Vuk”-os példamondatnál a Vuk, mint entitás nagyon erős szalienciát mutat a szöveg egészéhez viszonyítva, a „red fox” már gyengébb, míg a „fairy tale” még gyengébb. (Bár itt nagyon rövid a szöveg ahhoz, hogy valós szaliencia-értékeket kaphassunk.)
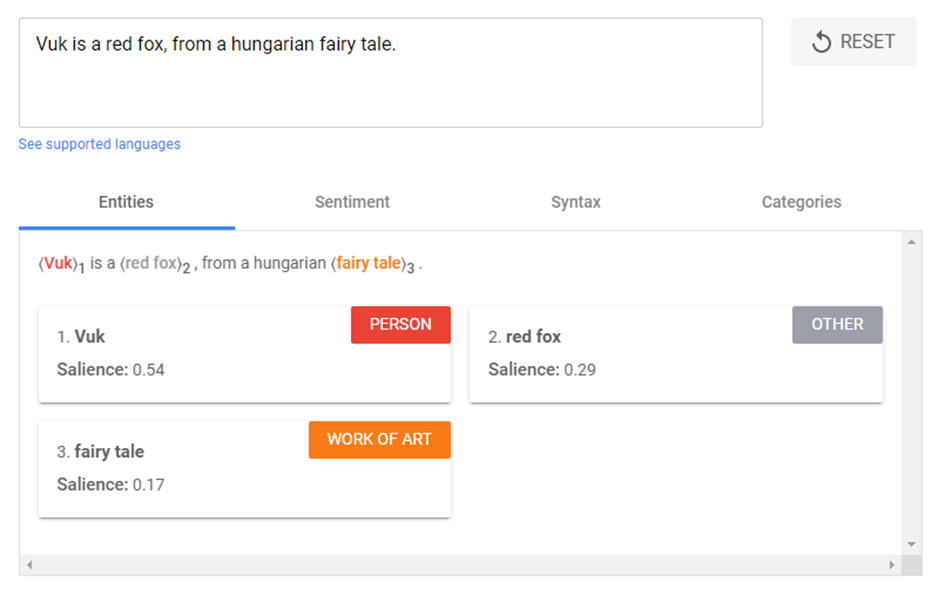
A szaliencia elemzés segítségével túlléphetünk a régi SEO-s kulcsszóismétlésen. Ha egy szövegben ugyanis előfordul a SEO, keresőoptimalizálás, Google, linképítés, webhelytérkép stb. szavak, akkor a Google tudja, hogy ezeknek a szavaknak a szalienciája erős, egymáshoz szorosan kapcsolódó fogalmakról van szó.
Éppen ezért nem kell folyamatosan a keresőoptimalizálás szót ismételgetni a szövegben, mert a szaliencia elemzés megmutatja, hogy a többi szó alapján a téma releváns a keresőoptimalizálásra.
Sentiment (Szentiment elemzés)
Ez érzelmi alapú elemzést jelent. A Google NLP képes a szöveg alapján meghatározni a tartalom pozitív vagy negatív érzelmi irányultságát.
Nézzük az alábbi példamondatot: „A tyúk utálja a rókákat, mivel megtámadja és lenyeli őket”
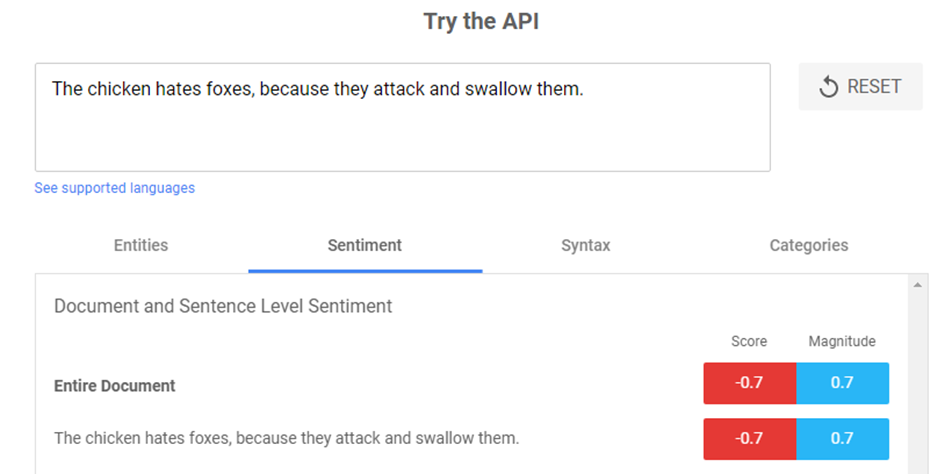
Látható, hogy ez a mondat igen negatív címkézést kapott. A szentiment elemzés, vagy nevezhetjük érzelmi polaritásnak is magyarul, -1 és +1 közötti értékeket vehet fel ugyanis.
A másik példa a pozitív érzületet mutatja: „A tyúk szereti a napfényes időjárást és az elragadó csibéket”. A sentiment értékelés 0,9-es pozitív értéket mutat.
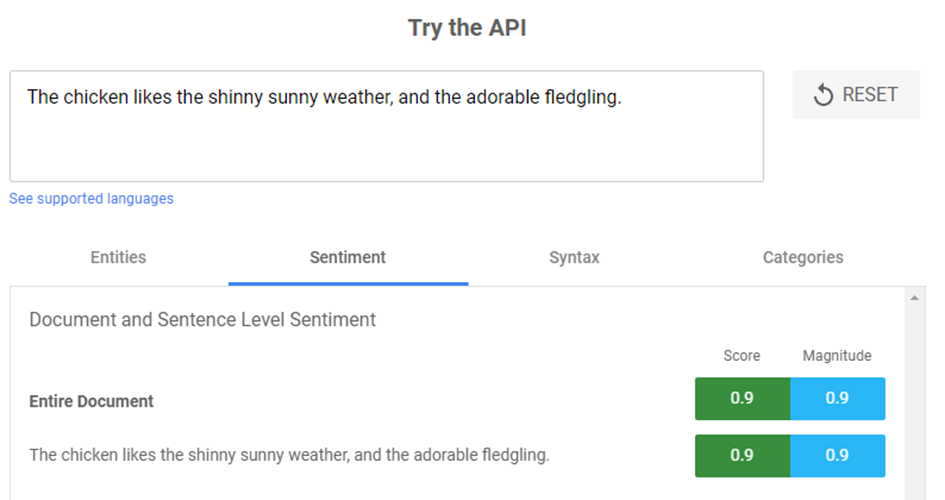
Jól látható tehát, hogy a Natural Language Processing képes a mondatok és a szöveg egészének hangulatát, érzelmeit elemezni és értelmezni.
Az érzékenységi elemzés köre kiterjedhet egy mondatra, egy bekezdésre, de akár a szöveg egészére is.
Téma kategorizálás
Az NLP ezen túl képes arra, hogy a szöveg témakörét meghatározza. Ennek köszönhetően képes arra, hogy tágabb értelemben meghatározza, hogy az adott oldal miről szól. (Nem mellékesen így meghatározható nem csak egy szöveg, de egy URL, vagy egy domain egészének szakértelme és autoritása is).
A Google kategorizálását itt találod.
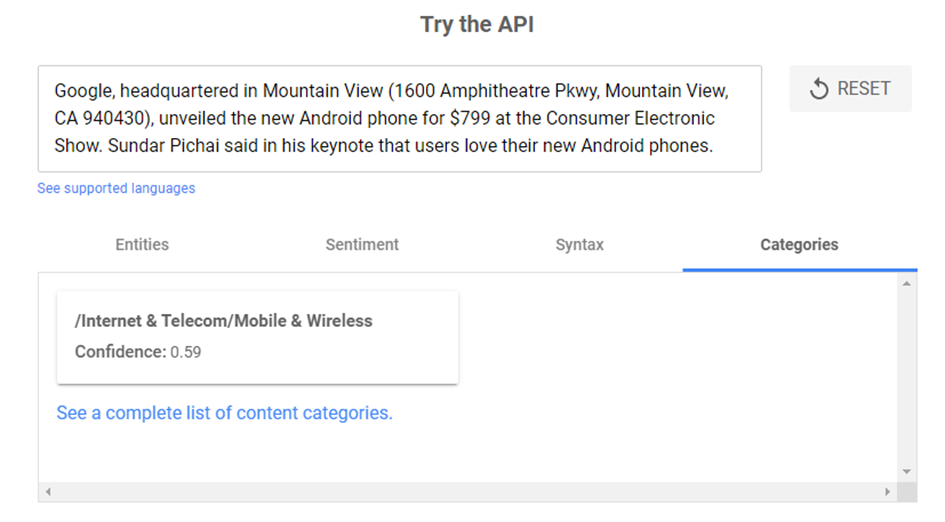
A Google NLP eredeti példamondatánál például, látható, hogy a szöveget a Google az Internet/Mobile&Wireless kategóriába sorolja.
A besorolás megbízhatóságát a Confidence érték jelzi, ami itt igen magas 0,59-es értékű.
Szöveg osztályozás és cél (Text classification and function)
A NLP ma már képes a szöveg elemzése során meghatározni a szöveg szándékolt funkcióját, vagy célját. Magyarán, hogy a szöveg milyen célból készült, milyen funkciót tölt be.
Ez természetesen nagyon jól használható a keresés során, hiszen a Google képes összevetni a keresőkifejezésben azonosított felhasználói szándékot a rangsorolásban felhasznált szövegek azonosított funkciójával.
Ez a gyakorlatban azt jelenti, hogy olyan típusú tartalmakat rangsorol adott keresőkifejezésre, amelyek funkciója összhangban van a feltételezett felhasználói szándékkal.
Tartalom típus kinyerése (Content type extraction)
A webes szöveg strukturális felépítésének és mintázatának elemzésével a keresőmotor az NLP segítségével képes meghatározni bizonyos tartalmak típusát, akár strukturált adatok jelölése nélkül is.
Például egy receptet, vagy egy eseményt, vagy egy termékoldalt, pusztán a szöveg felépítése, mintázata alapján is tud típusba sorolni.
Tartalomelemzés a struktúra alapján
A szöveg formázása, például listák, felsorolások, sortörések, címsorok, vagy éppen egyes tartalmi elemek fizikai közelsége képes a szöveg implicit értelmén módosítani, vagy annak másodlagos jelentést adni.
Például, ha a címsorok számokkal kezdődnek, az jó eséllyel valamilyen lista, vagy rangsorolásszerű tartalomra utal. Ez független lehet a HTML kódolástól, a szöveg vizuális megjelenése a renderelés során (betűméret, vastagság) önmagában is utalhat erre.
Az NLP használata a keresésben
Ahogy a szemantikus keresésről írt cikkben írtam a Google 2019 óta, a BERT algoritmus megjelenésétől kezdve használja elismerten a természetes nyelvek feldolgozását. Ezt követte 2021-ben a MUM algoritmus.
De mire használja a Google az NLP-t?
- a felhasználó keresőkifejezéseinek értelmezése szemantikai alapon
- a webes dokumentumok osztályozása és céljának meghatározása
- entitás azonosítás és webes szövegekben, közösségi média posztokban
- Tudásgráf bővítése
- webes szövegek jobb értelmezése (ezen belül a szöveg kontextus jobb értelmezése, jelentéstartalmú elemzés, saliencia elemzés, stb.)
Fontos látni, hogy az NLP használata két területen történik. Egyrészt a felhasználó keresőkifejezésének jobb értelmezése, másrészt a webes szövegek jobb minőségű elemzése. A kettő közül jelenleg talán az első a fontosabb, mert megkönnyíti a releváns találati lista összeállítását.
A másik fontos dolog, amit kiemelnék az az entitások jobb azonosítása a webes szövegekben. A Google 2020-ig jórészt a Wikipédia szerű adatbázisokra tudott csak támaszkodni, amikor entitásokról volt szó. Az NLP megjelenésével lehetővé vált számára, hogy entitásokat és azok tulajdonságait kibányássza a webes szövegekből.
Ez pedig hosszabb távon még jobb szövegértelmezést tesz lehetővé, és a hagyományos kifejezés alapú rangsorolás elmozdulhat az entitás alapú rangsorolás irányába.
A természetes nyelvek feldolgozása és a SEO
Hogyan használhatjuk tehát mindezt a tudást a keresőoptimalizálásban?
A jó hír az, hogy igazából nehéz olyan dolgot mondani, ami ne hangozna ismerősnek annak, aki a hagyományos SEO-ban járatos.
A jobb szövegértelmezéssel a tartalom nem csak király, hanem egyenesen császári rangra emelkedik. Azt azonban hozzá kell tenni, hogy mindez igazán jól csak angol nyelven működik. De nem kérdés, hogy ez a jövő magyar nyelven is.
Ha nem akarod túlbonyolítani a dolgot, akkor a tanács ugyan az, ami korábban is. Írj kiemelkedő minőségű tartalmat, ami kiszolgálja a felhasználó keresési szándéka mögött lévő információigényt.
De lássunk néhány konkrét SEO ötletet!
- Használd a Google NLP API-ját, ezzel a cikkben bemutatott elemzések jó része elvégezhető. A SEO Klub tanfolyamában erre mutatok konkrét példákat (a Klubba október 1-től lesz ismét belépési lehetőség, iratkozz fel a várólistára).
- Használj releváns entitásokat a szövegeidben és ügyelj arra, hogy ezek egyértelműek legyenek a magyar nyelv használat mellett is! A cikksorozat további részében külön fejezet cikk lesz szentelve az entitásoknak
- A belső linkek szerepe megnő, de az eddigi relevancia és linkerő mellet a belső linkek kontextusa is számít.
- Figyelj a szentiment elemzésre! Ha a találati listát pozitív érzelmű tartalmak uralják, ez utal a felhasználói szándékra a témával kapcsolatban, amit neked is célszerű követned, ha jó helyen akarsz rangsorolni
- A kulcsszóhalmozás és az LSI kulcsszavak helyett a saliencia legyen a középpontban, mert ez adhatja meg szövegeid relevanciáját
- Ügyelj arra, hogy a szövegeid funkciója és kategorizálása egyértelmű legyen, ha a felhasználói szándék jól meghatározható a keresőkifejezés alapján
- Az NLP nem csak a te szövegeidnél él, hanem a felhasználói keresőkifejezések elemzésekor. Ügyelj rá, hogy szövegeid jól illeszkedjenek a felhasználói szándékhoz. Lásd meg, milyen tartalomtípusokat vár el a felhasználó
- Ügyelje a webes szövegeid szemantikai formázására!
NLP zárszó
Remélem sikerült kicsit közelebb hoznom számodra a szemantikus keresés és a természetes nyelvek feldolgozásának folyamatát és kicsit közelebb került hozzád a keresőmotorok mai működése.
A cikksorozat következő részeiben az entitásokról és a tudásgráfról lesz majd szó.

Töltsd le a Google 100 keresőoptimalizálási tanácsát
...és értesülj a legfontosabb SEO hírekről. 100% SEO, zéró spam.
Mint mindig, most is nagyon érdekes olvasni. Köszönjük a munkáját!