
(Ez egy cikksorozat első része, amely a modern SEO-val foglalkozik: szemantikus SEO, entitások, NLP, Tudásgráf, stb. Ha érdekel a folytatás, iratkozz fel a hírlevélre.)
Ha használod az angol nyelvű Google keresőt, akkor nyilván feltűnt számodra, hogy a Google milyen jól tudja értelmezni a felhasználó kérdését és a mögötte lévő szándékot. Ez magyar nyelven egyelőre még döcög, de itt is látványos a fejlődés. Mindezt a szemantikus keresés fejlődése tette lehetővé.

Ebből a cikkből megtudhatod, hogy:
- mi a szemantikus keresés?
- miért fontos ez a keresőmotoroknak?
- hogyan alakult ki a szemantikus keresés?
- miért fontos ez a keresőoptimalizálás számára és hogy mi a szemantikus SEO?
Mi az a szemantikus keresés?
A szemantikus keresés egy információ kinyerési folyamat, amelyet a modern keresőmotorok használnak annak érdekében, hogy a lehető legrelevánsabb találatokat nyújtsák a keresőknek.
A szemantikus keresés értelmezi a felhasználó szándékát, a keresőkifejezés kontextusát és a szavak közötti kapcsolatot, szemben a hagyományos kulcsszó alapú egyezőséggel.
Maga a szemantika szó jelentéstant jelent, és a nyelvészettudomány egyik területe, de ma már gyorsan tágul a szó jelentéstartalma..
Hirdetés

Miért fontos a keresőmotoroknak a szemantikus keresés?
A keresőmotorok piaci előnye azon alapul, hogy minél jobb találati listát adjanak a felhasználó keresésére. A Google sikerét a link alapú rangsorolás adta a 2000-es évek elején.
A szemantikus keresés megjelenése hasonló áttörést jelent. Ennek segítségével ugyanis a keresőmotorok nem csak kulcsszavakat keresnek a felhasználó keresőkifejezése alapján, hanem megpróbálják értelmezni a felhasználó keresése mögötti szándékot, és értelmezik annak jelentéstartalmát.
Nézzünk néhány konkrét példát miért van szüksége a szemantikus keresésre a keresőmotoroknak!
A felhasználók gyakran nem úgy keresnek, ahogy a kívánt tartalom fogalmaz
Az alábbi keresésben megadtam, hogy egy olyan pop számot keresek a 80-as évekből, amiben fekete-fehér képregényben az énekes megment egy lányt.

Látható, hogy a kereső azonnal kiadta a keresett számot, holott nem adtam meg sem az előadó nevét, sem a szám címét.
Rengeteg olyan keresés történik a weben, amikor a felhasználók nem kulcsszavakkal keresnek, hanem csak homályos elképzeléseik vannak arról mi is keresnek pontosan. Gondolj csak arra, amikor például betegségtünetre keresnek rá.
A szemantikus keresés segítségével ezek a felhasználói keresések értelmezhetőek és sokkal jobb találat adható rájuk.
Ez a fajt keresés különösen igaz a Z generációra, akik nem kulcsszavakkal, hanem élőbeszéd-szerűen használják a Google-t.
A keresőkifejezések többértelműek
A keresőmotorok számára az egyik legnagyobb kihívást az jelenti, hogy a legtöbb szó többértelmű. Az angol szavak 40%-a több jelentéstartalommal is bír, és ez a legtöbb nyelvre igaz.
A többjelentésű szavak értelmezéséhez a kontextus ad segítséget a keresőrobotoknak, azaz, ha a keresőkifejezéseket nem önállóan hanem együttesen értelmezik (esetleg figyelembe véve a felhasználó korábbi kereséseit is).
Gondolj csak az „esőtánc” szóra. Vajon mit akar a felhasználó? Az ilyen nevű weboldalt? Az cselekvésről szeretne többet tudni, vagy a zeneszámra kíváncsi? Az ilyen többértelmű kifejezések feldolgozását is segíti a szemantikus keresés.

Entitások azonosítása
Nézzük meg az alábbi keresést!
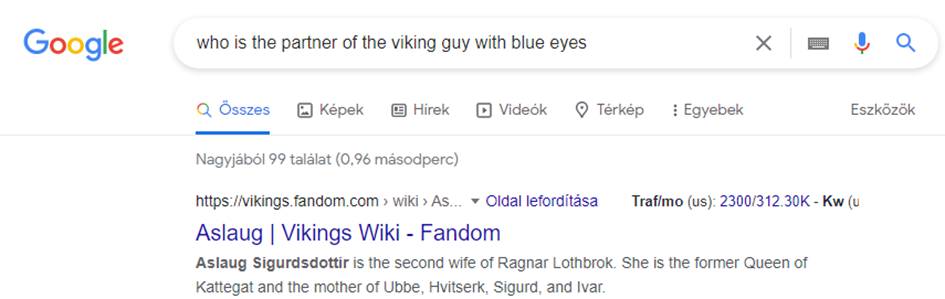
A Google szemantikus keresés nagyon jól teljesített. Képes volt értelmezni, hogy:
- a partner szó mit jelent (itt feleség)
- tudta értelmezni, hogy egy személyre vagyok kíváncsi
- tudta értelmezni, hogy egy viking ember valakijére vagyok kíváncsi
- akiről annyit tudok, hogy kék szeme van
Ezek alapján, noha nincsenek konkrét filmcímek, vagy személynevek megadva, sőt az sem, hogy én valós vagy képzelt személyt keresek mégis pontos választ adott.
Ez az entitásokon alapul, amiről később még lesz szó, most legyen elég annyi, hogy az entitások olyan létező egyedi dolgok, vagy fogalmak, amelyek segítik a szemantikus szövegértelmezést.
Az én keresésem alapján a Google több entitást is azonosított. Képes volt:
- azonosítani a sorozatot mint entitást,
- képes volt entitásként azonosítani a színészt a kék szemmel, aki szerepelt a sorozatban
- majd képes volt meghatározni annak a partnerét, aki szintén egy entitás.
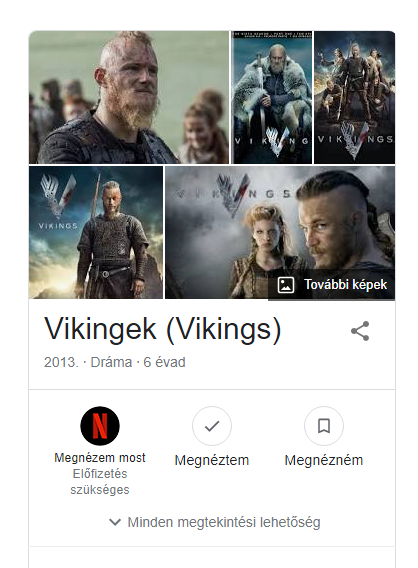
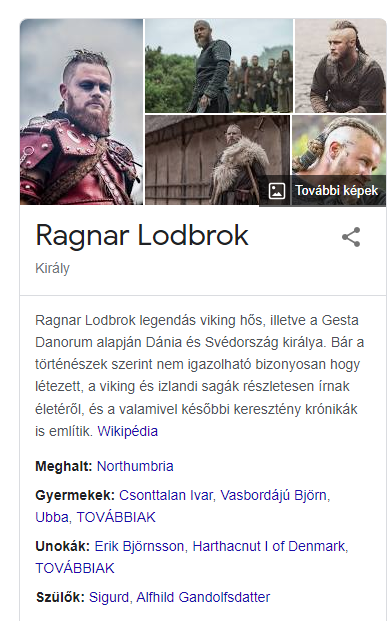
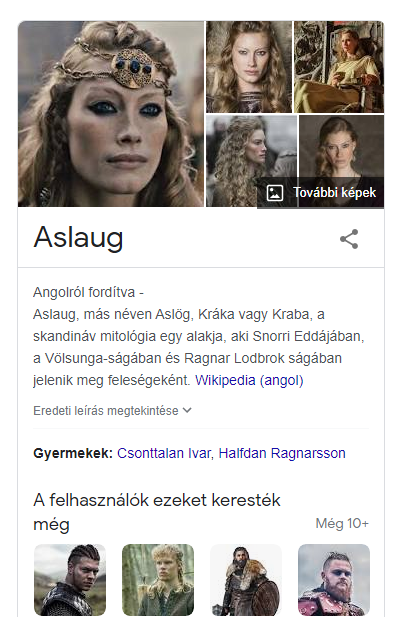
És végül a megfelelő találatot adta a keresésemre.
Az entitások azonosítása kulcsszerepet játszik a szemantikus keresésben, mert innentől a keresőkifejezések nem csak szavak, hanem valós létezők, vagy valós emberi fogalmak.
A sort lehetne még folytatni, hogy hol és hogyan használják a szemantikus keresést a keresőmotorok, de nézzük meg most, hogy hogyan jött létre a szemantikus keresés, így talán a fogalom is világosabbá válik.
A szemantikus keresés története és kialakulása
Keresés a szemantikus forradalom előtt
Nagyjából 2012-ig a keresőmotorok egész egyszerűen betűket elemeztek a weben. Bár láthatták azt a szót, hogy „keresőoptimalizálás” ennek nem volt jelentése számukra, csak betűk halmaza volt, egy szó, mindenféle értelem nélkül.
Ezért működtek eleinte olyan technikák, mint a kulcsszóhalmozás, hiszen a keresőmotorok olyan szavakat kerestek a szövegben, ami azonos a felhasználó keresésével.

Ez a későbbiekben rengeteget finomodott, de 2012-ig alapvetően a keresőmotorok karaktereket elemeztek.
Ez változott meg 2012-ban, a Tudásgráf, majd a Kolibri-algoritmus megérkezésével. Ekkor köszöntött be a szemantikus web kora, amikor a szavaknak már „jelentése” lett a keresőrobotok számára – mégha, nem is emberi értelemben.
A szemantikus web megszületése
A szemantikus web, célja, hogy az interneten lévő tartalmak a gépek számára értelmezhető és megérhető adatokká váljanak.
Érdekes módon a szemantikus web fogalma és maga a kifejezés is Tim Berners-Lee nevéhez kötődik, aki az internet feltalálója, és már 1999-ben írt a szemantikus web-ről.

Hogyan jutottunk el a szemantikus keresésig?
Hogy megértsük ennek jelentőségét, tegyünk egy kis időutazást!
Az internet felfedezése előtt egy tudományos publikációban, vagy egy könyvben hivatkozások voltak. Ha valaki ezeket meg akarta találni el kellett mennie egy könyvtárba, hogy a keresett információt megtalálja. Az információk összekötése tehát csak fizikailag volt megoldott.
Az internet megjelenésével a web 1.0-val ez változott meg radikálisan, hiszen a dokumentumok, és a benne lévő információk linkekkel összeköthetőekké váltak. Megszűnt a fizikai kényszer és létrejött a dokumentumok láncolata.
A web 2.0 meghozta a mobil appok, a felhőtechnológiák és a közösségi média korát, de a dokumentumok és információk továbbra is strukturálatlan formában voltak jelen az interneten.
A web 3.0 ebben hozott áttörést, mivel megszületett a szemantikus web. Ez azt jelentette, hogy weboldalakon lévő tartalmak egyre nagyobb része válik gépekkel megérthetővé (szemantikus web).
Míg a web 1.0 weblapokat kötött összelinkeken keresztül, a web 3.0 már nem csak dokumentumok szintjén, hanem elemi entitások, adatok szintjén kapcsolódik össze.
Éppen ezért a keresőmotorok ma már nem a felhasználó által beírt kulcsszót látnak, hanem értelmezik és megértik a felhasználó szándékát és a kontextust is az entitásoknak köszönhetően.
A régi keresőmotorok lexikálisak voltak. A felhasználó által megadott kulcsszót keresték a szövegben, éppen ezért a szöveg hossza és a kulcsszósűrűség számított.
Ma már értelmezik a szöveget, entitásokat keresnek, az entitások kontextusát, és az egyes entitások közötti korreláció erősségét vizsgálják.
Röviden összefoglalva a szemantikus keresés során a keresőmotorok már értelmezik a felhasználó keresési szándékát, a keresőkifejezés szélesebb összefüggéseit és az egyes szavak, entitások közötti összefüggéseket, hogy minél jobb találatiot adjanak.
A Google Tudásgráf megszületése (2012)
A Google Tudásgráfja (Knowledge Panel) 2012-ben indult útjára. Ekkor mintegy 500 millió entitás, és 3,5 milliárd kapcsolat, tény, tulajdonság kötődött hozzá.
A Tudásgráf látható formában a Tudáspanelek formájában jelenik meg a találati listán. Ahol entitások (személyek, helyek, dolgok, fogalmak) rövid leírása és kapcsolatai, valamint tulajdonságai láthatóak.
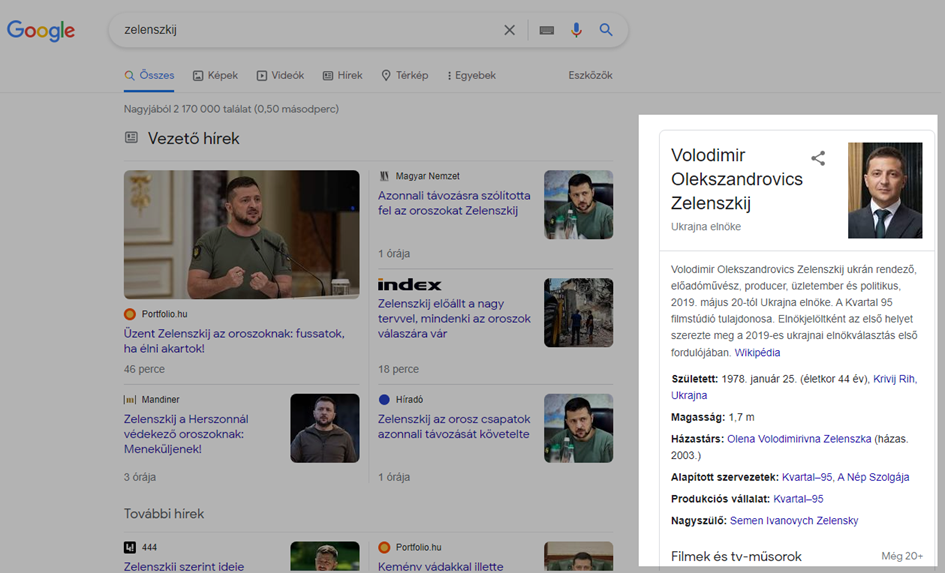
2020 májusára már 5 milliárd entitást és 500 milliárd tényadatot tartalmazott a tudásgráf. Az ezek közötti kapcsolati háló nagysága elképzelhetetlenül nagy.
A Tudásgráf segítségével a Google entitások és azok közötti kapcsolatokat lát, így a felhasználó keresésében is és a webes szövegekben is tud entitásokat keresni. Ez jobb szövegértelmezést tesz lehetővé és jobb találati listát is.
A Tudásgráf adatokat lekérheted az ite.hu SEO eszközén is: http://tools.ite.hu/entity.php

Kolibri-algoritmus (2013)
A Google 2013-ban indította útjára a Kolibri-algoritmust, utoljára hasonló mértékű radikális változás 2001-ben volt a Google keresőalgoritmusában. A Kolibri algoritmus volt az áttörés, mert innentől a Google már nem kulcsszó-keresőként működött, hanem szemantikus keresőként.
Scott Huffman a Google mérnöke szerint ezzel a lépéssel a keresőmotor elindult afelé, hogy az emberi beszélgetésekhez hasonló párbeszéd történhessen a felhasználó és a keresőmotor között.
A Google magyarázata szerint a Panda, és Pingvin algoritmusok a régi motor alkatrészeinek cseréje volt. A kolibri algoritmussal az egész motort cserélték le.
RankBrain algoritmus (2015)
A RankBrain algoritmus további előrelépést jelentett a szemantikus web irányába. A radikális változás itt az volt, hogy a Google ezzel az algoritmussal elindult a gépi tanuláson alapuló technológiák felé.
A RankBrain algoritmus különösen azoknál a kereséseknél volt hasznos, amelyet a Google korábban nem látott még (a keresések 15%-a teljesen új a kereső számára).
A RankBrain algoritmus a kereső számára idegen, vagy bizonytalan keresőkifejezéseknél vektor-tér elemzést hajt végre, hogy megtalálja azokat az entitásokat, amelyek legszorosabb kapcsolatban vannak a keresőkifejezéssel. A kontextus elemzéséhez pedig a kapcsolódó szavakat használja.
Röviden összefoglalva ez is egy előrelépést jelentett a szövegek jobb értelmezéséhez.
BERT-algoritmus (2019)
A BERT algoritmus (Bidirectional Encoder Representations from Transformers) újabb mérföldkő a szemantikus keresésben, amelyet a keresőkifejezések 10%-ánál használ a Google és magyar nyelven is él.
A BERT már az NLP-n alapul, amely a Natural Language Processing betűszava. Az NLP egy olyan mesterséges intelligencia, ami segíti a számítógépeket, hogy feldolgozza és megértse a természetes nyelveket (erről a cikksorozat következő részeiben olvashatsz részletesen).
A természetes nyelvek feldolgozását a Google számos területen alkalmazza:
- felhasználói keresések értelmezése
- webes dokumentumok tárgyának és cáljának értelmezése, entitás elemzés
- rangsorolás
- videó és hang tartalmak értelmezése
- tudásgráf bővítése és fejlesztése
Az NLP jelentőségét nehéz érzékeltetni, de talán jó példa a hasznosságára, hogy az NLP, képes egy- egy szöveg, vagy mondatban a szöveg hangulatának pozitivitásáanak elemzésére és értékelésére is.
MUM-algoritmus
A MUM algoritmus 2021-ben jelent meg és újabb előrelépést jelent. Legfőbb jellemzője, hogy többnyelvű, azaz a nyelveket már nem elszeparáltan kezeli, és képes videó és hangfájlok valamint képtartalmak elemzésére is.
Mit jelent a szemantikus keresés a keresőoptimalizálás számára? Mi az a Szemantikus SEO?
Remélem a fentiek tisztázták benne, hogy mit is jelent a szemantikus keresés, és hogy miért volt hatalmas áttörés ez a 2010-es évek elején. Ez a forradalom azóta is zajlik, mégha talán nem is túl látványos formában. Az egyértelmű, hogy legerősebb hatását angol nyelvterületen fejti ki, de az eredmények folyamatosan jelentkeznek a magyar weben is.
Ennyi elméleti ismeret után felmerülhet benned, hogy mindezt hogyan használjam a gyakorlati SEO-ban, és hogy mit jelent a szemantikus keresés a saját weboldalamra nézva?
A szemantikus SEO-val egy külön cikk fog foglalkozni, de röviden a főbb jellemzőket, azért előzetesen ismertetem.
Íme a szemantikus SEO főbb jellemzői:
- Ne kulcsszavakra, hanem témakörökre írj tartalmat: ahogy a Google egyre jobban képes értelmezni a szöveget, egyre kevésbé szükséges egymáshoz közel álló témáknak külön aloldalakat készíteni.
- Optimalizálj a felhasználói szándékra: mielőtt tartalmat készítenél nézd meg, mi a felhasználói szándék. Nem fogsz tudni olyan tartalomtípussal rangsorolni, ami nem illeszkedik a felhasználó szándékához. Hiába írsz egy remek cikket a laptopokról, ha az emberek alapvetően webáruházas tartalmat szeretnének erre a keresőkifejezésre.
- Használj strukturált adatokat, ahol csak lehet: és itt nem csak azokra gondolok, amik speciális megjelenést biztosítanak a találati listára, hanem arra a több szász strukturált adat lehetőségre, amit megtalálsz a schema.org-on, ami a keresőmotorok közös weboldala.
- Használj entitásokat: amikor tartalmakat készítesz gondolj entitásokban is, ez ugyanis erősíti a szöveged relevanciáját
- Építs topológiai relevanciát belső linkekkel: Kapcsold össze az egymással összekapcsolódó tartalmakat, ahogy a Tudásgráf is összeköti az entitásokat.
- Használj szemantikus HTML-t: bár nem tartom kiemelten fontosnak, ha megoldható érdemes áttérni a szemantikus HTML használatára, ha már a HTML5 ezt lehetővé teszi.
A sort lehetne folytatni, de ahogy írtam a szemantikus SEO-val részletesen egy külön cikkben foglalkozom majd.
A cikksorozatban külön cikket írok majd:
- a NLP-ről és ennek SEO használatáról
- entitásokról és entitás SEO-ról
- szemantikus SEO-ról a gyakorlatban
És ha van rá igény, akkor a SEO új irányvonalának többi eleméről is.
Remélem hasznosnak találtad a szemantikus keresésről írtakat, mégha ez a cikk kissé elméleti jellegű is. Ha érdekel a többi cikk, iratkozz fel a hírlevéllistára és értesítelek majd az új tartalmakról a szemantikus SEO témaköréből.
Ez a cikk SEO Klubban megjelent Szemantikus SEO-ról szól videótanfolyam rövidített változata.

Töltsd le a Google 100 keresőoptimalizálási tanácsát
...és értesülj a legfontosabb SEO hírekről. 100% SEO, zéró spam.
A hazai honlapok felépítése, linképítési technikája, szemléletmódja meglehetősen hasonló kaptafára utal.
Aki előzni akar, vagy tartani megszerzett pozícióit, vagy ügyfeleit versenyképesebb helyzetbe akarja hozni, jól teszi, ha egyelőre a periférián helyet foglaló eszközökre és módszerekre is figyel és felhasználja azokat.
Ezért nagyszerű a téma felhozatala!
A Látens Szemantikai Indexelés (LSI) egy logikai sor középső eleme.
Az egymásra épülő, minőségében bővülő logikai sor elemei: szinonímák – látens szemantikai indexelés (Latent Semantic Indexing) – érintőleges tartalom (Tangential Content Ideas).
Az angol nyelvterületen már régebb óta LSI generátor is működik. Mi még a saját bio-generátorunkban bízhatunk csak 🙂
Köszi. A többi cikk reményeim talán még érdekesebb lesz.
Az LSI kapcsán: igazából a Google soha nem használta az LSI-t. Ez egy 1980-as évekből származó szabadalom, ami nem is a Google nevéhez kötődik és a szabadalom csak 2008-ban járt le, akkor pedig már régen meghaladta az idő. Ettől függetlenül az, amiről szól az LSI a gyakorlatban valóban jól használható a keresőoptimalizálásban, mégha a konkrét szabadalmakkal körülírható LSI-t deklaráltan nem alkalmazza a Google.
Ebből aztán külföldön elég nagy viták vannak szakmai körökben. A fundamentalisták szerint az LSI-t nem használja a Google, ezért nem is kell vele foglalkozni, a gyakorlatibb megközelítésűek viszont használják a fogalmat, mert a koncepció, ami a gyakorlatban működik jól leírható a fogalommal.